HERA: A Hierarchical-Compensatory Ranking Framework for Paired Benchmarking with Data-Driven Effect-Size Thresholds
Lukas von Erdmannsdorff
Institute of Neuroradiology, Goethe University Frankfurt
Summary
In scientific disciplines ranging from clinical research to machine learning, researchers face the challenge of objectively comparing multiple algorithms, experimental conditions, or datasets across up to three performance or quality metrics. This process, often framed as Multi-Criteria Decision Making (MCDM), is critical for identifying state-of-the-art methods. However, traditional ranking approaches frequently suffer from limitations: they may rely on central tendencies that ignore data variability (Benavoli et al., 2016; Demšar, 2006), depend solely on p-values which can be misleading in large samples (Wasserstein & Lazar, 2016), or require subjective weighting of conflicting metrics (Taherdoost & Madanchian, 2023).
HERA (Hierarchical-Compensatory, Effect-Size-Driven Ranking Algorithm) is a MATLAB-based ranking framework designed to automate the Paired Benchmarking process, bridging the gap between elementary statistical tests and complex decision-making methods. Unlike weighted-sum approaches that collapse multi-dimensional performance into a single scalar, HERA implements a hierarchical-compensatory logic. This logic integrates non-parametric significance testing (Wilcoxon signed-rank test), robust effect size estimation (Cliff’s Delta, Relative Difference), and bootstrapping (e.g. Percentile and Cluster) to produce rankings that are both statistically robust and practically relevant. HERA is designed for researchers in biomedical imaging, machine learning, and applied statistics who need to compare method performance across multiple quality metrics in a statistically rigorous manner without requiring subjective parameter tuning.
Statement of Need
The scientific community increasingly recognizes the pitfalls of relying on simple summary statistics or p-values alone (Wasserstein & Lazar, 2016). In benchmarking studies, specifically, several issues persist:
- Ignoring Variance: Ranking based on mean scores fails to account for the stability of performance across different subjects or folds. A method might achieve a high average score due to exceptional performance on a few easy cases while failing catastrophically on others, yet still outrank a more consistent competitor (Demšar, 2006).
- Statistical vs. Practical Significance: A result can be statistically significant but practically irrelevant, especially in large datasets where even trivial differences yield p < 0.05. Standard tests do not inherently distinguish between these cases, potentially leading to the adoption of methods that offer no tangible benefit (Sullivan & Feinn, 2012).
- Subjectivity in Aggregation: Many MCDM methods require users to assign subjective weights to metrics (e.g., “Accuracy is 0.7, Speed is 0.3”). These weights are often chosen post-hoc or lack empirical justification, introducing researcher bias that can be manipulated to favor a specific outcome (Taherdoost & Madanchian, 2023).
- Distributional Assumptions: Parametric tests (e.g., t-test) assume normality, which is often violated in real-world benchmarks where performance metrics may be skewed, bounded, or ordinal (Romano et al., 2006).
HERA addresses these challenges by providing a standardized, data-driven framework. It ensures that a method is only ranked higher if it demonstrates a statistically significant and sufficiently large advantage, preventing “wins” based on negligible differences or noise. Existing MCDM software packages such as the Python libraries pyDecision (Pereira et al., 2024) and pymcdm (Kizielewicz et al., 2023), or R’s RMCDA (Najafi & Mirzaei, 2025) often implement classical methods like TOPSIS (Hwang & Yoon, 1981), PROMETHEE (Brans & Vincke, 1985), and ELECTRE (Roy, 1968) that require user-defined weights or preference functions. With HERA, subjective parameterization is reduced by using data-driven thresholds derived from bootstrap resampling. Furthermore, the framework integrates statistical hypothesis testing directly into the ranking process, a feature absent in standard MCDM toolboxes. By unifying strictly paired statistical inference with adaptive hierarchical-compensatory logic, the algorithm establishes an improved methodological paradigm. This framework fills a critical gap across scientific software ecosystems—including MATLAB—by providing a dedicated, open-source environment for statistically rigorous, multi-criteria benchmarking that minimizes both subjective weighting and the need for ad-hoc scripting.
Methodological Framework
HERA operates on paired data matrices where rows represent subjects (or tests) and columns represent the candidates to be compared. The core innovation is its sequential logic, which allows for “compensation” between metrics based on strict statistical evidence.
Statistical Rigor and Effect Sizes
HERA quantifies differences using statistical significance and effect sizes to ensure practical relevance independent of sample size (Cohen, 1988; Sullivan & Feinn, 2012). A “win” always requires satisfying three conjunctive criteria, if not it is considered “neutral”:
- Significance: p < αHolm (Holm-Bonferroni corrected). Pairwise comparisons use the Wilcoxon signed-rank test (Wilcoxon, 1945), with p-values corrected using the step-down Holm-Bonferroni method (Holm, 1979) to control the Family-Wise Error Rate (FWER).
- Stochastic Dominance (Cliff’s Delta): Cliff’s Delta (d = P(X>Y) − P(Y>X)) quantifies distribution overlap, is robust to outliers, and relates to common-language effect sizes (Cliff, 1993; Vargha & Delaney, 2000). The effect size d must exceed a bootstrapped threshold θd.
- Magnitude (Relative Difference): The Relative Mean Difference (RelDiff) quantifies effect magnitude on the original metric scale, defined for group means x̄ and ȳ as: $\text{RelDiff} = \frac{\vert\bar{x} - \bar{y}\vert}{\vert\frac{1}{2}(\bar{x} + \bar{y})\vert}$. This normalization is formally identical to the Symmetric Mean Absolute Percentage Error (SMAPE) used in forecasting (Makridakis, 1993). However, by being applied to group means rather than individual observations, it becomes a distinct between-group measure of practical magnitude, conceptually related to the Response Ratio in meta-analysis (Hedges et al., 1999). The metric enables scale-independent comparisons and facilitates the interpretation of percentage changes (Kampenes et al., 2007). RelDiff must exceed a threshold θRelDiff.
- Complementary Criteria & SEM Lower Bound: HERA’s complementary logic requires statistical significance, stochastic dominance and practical magnitude, preventing “wins” based on trivial consistent differences or noisy outliers. This approach is conceptually aligned with the recommendation to evaluate both significance and effect sizes for a comprehensive assessment of experimental results (Lakens, 2013). Thresholds are determined via Percentile Bootstrapping (lower α/2-quantile) (Rousselet et al., 2021). To filter trivial effects (e.g. in low-variance datasets), the RelDiff threshold enforces a lower bound based on the Standard Error of the Mean (SEM), ensuring θRelDiff ≥ θSEM. This approach is inspired by the concept of the “Smallest Worthwhile Effect” (Hopkins, 2004), but adapted for HERA to quantify the uncertainty of the group mean rather than individual measurement error.
Hierarchical-Compensatory Logic
The ranking process is structured as a multi-stage tournament. It does not use a global score but refines the rank order iteratively (see Fig. 1):
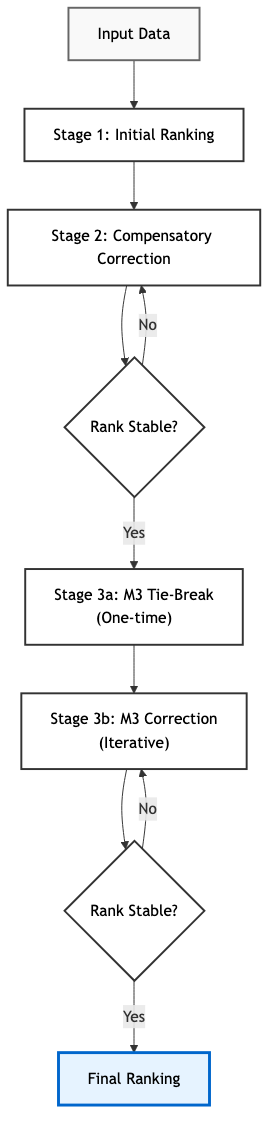
- Stage 1 (Initial Sort): Methods are initially ranked based on the win count of the primary metric M1. In case of a tie in adjacent ranks, Cliff’s Delta is used to break the tie. If Cliff’s Delta is zero, the raw mean values are used to break the tie.
- Stage 2 (Compensatory Correction): This stage addresses the trade-off between metrics. A lower-ranked candidate can “swap” places with a higher-ranked one if it demonstrates a statistically significant and relevant superiority in the secondary metric M2. In this hierarchy, M2 acts as a strict veto mechanism: a significant disadvantage in this critical metric (e.g. critical safety concerns) cannot be offset by any magnitude of advantage in M1. This effectively implements a hierarchical-compensatory ordering (Keeney & Raiffa, 1976), allowing candidates that are worse in the primary metric but superior in a secondary metric to correct the rank order.
- Stage 3 (Tie-Breaking): This stage resolves
“neutral” results using a tertiary metric M3. It applies two
distinct sub-logics to ensure a total ordering while maintaining
hierarchical stability:
- Sublogic 3a (Local Correction): A one-time correction for adjacent pairs if the previous metric (M2) is neutral. This handles cases where two methods are indistinguishable in the higher-priority criteria, allowing M3 to locally correct the initial order without triggering cascading chain reactions that could destabilize the global hierarchy.
- Sublogic 3b (Indifference Resolution): To resolve clusters of remaining undecided methods, an iterative correction loop is applied to subsets where both M1 and M2 are “neutral,” utilizing metric M3 until a final stable order is found.
Validation and Uncertainty
HERA integrates advanced resampling methods to quantify uncertainty:
- BCa Confidence Intervals: Bias-Corrected and Accelerated (BCa) intervals are calculated for all effect sizes in the pairwise comparisons for each metric (Efron, 1987).
- Cluster Bootstrap: To assess the stability of the final ranking, HERA performs a cluster bootstrap resampling subjects with replacement (Field & Welsh, 2007). This yields a 95% confidence interval using the percentile method for the achieved ranks of each method.
- Power Analysis: A post-hoc simulation with cluster-bootstrap estimates the relative frequency of detecting a “win”, “loss” or “neutral” result in all pairwise comparisons per metric given the data characteristics.
- Sensitivity Analysis: The algorithm permutes the metric hierarchy and aggregates the resulting rankings using a Borda Count (Young, 1974) to evaluate the robustness of the decision against hierarchy changes.
Software Features
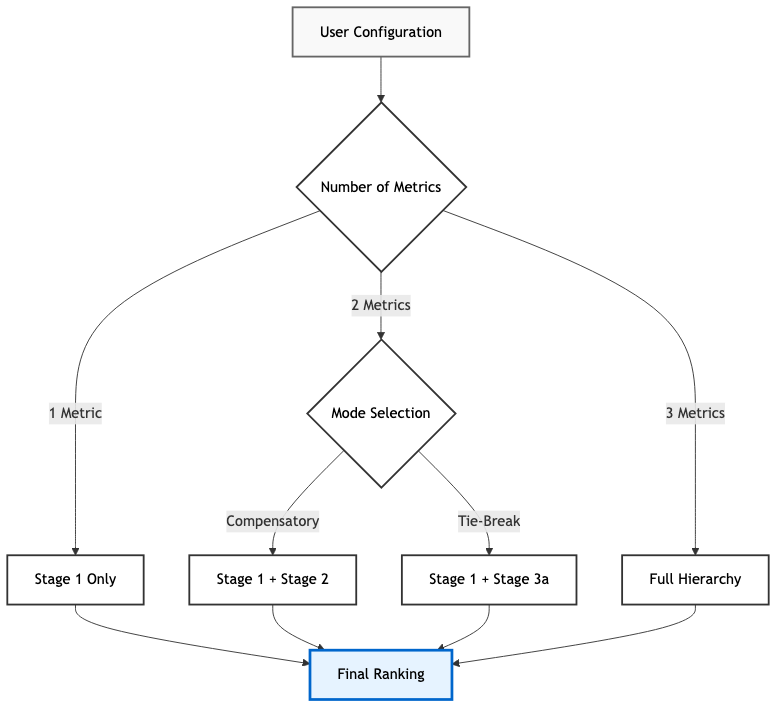
HERA offers a flexible configuration of up to three metrics (see Fig. 2). This allows users to adapt the ranking logic to different study designs and needs. It also combines this flexibility with a range of reporting options, data integration, and reproducibility features. By providing robust default parameters for all statistical and convergence settings, researchers can focus exclusively on core scientific decisions—such as the selection of metrics, the choice of ranking logic, and the assignment of metrics to the specific stages—while all technical tuning and validation steps are fully automated. This allows the ranking process to directly reflect the user’s scientific expertise without requiring ad-hoc parameterization.
- Automated Reporting: Generates PDF reports, Win-Loss Matrices, Sankey Diagrams, and machine-readable JSON/CSV exports.
- Reproducibility: Supports fixed-seed execution and configuration file-based workflows. The full analysis state, including random seeds and parameter settings, is saved in a JSON file, allowing other researchers to exactly replicate the ranking results.
- Convergence Analysis: To avoid the common pitfall of using an arbitrary number of bootstrap iterations, HERA implements an adaptive algorithm. It automatically monitors the stability of the estimated confidence intervals and effect size thresholds, continuing the resampling process until the estimates converge within a specified tolerance, thus determining the optimal number of iterations B dynamically (Pattengale et al., 2010). If the characteristics of the data for bootstrapping are known, the number of bootstrap iterations can be set manually.
- Data Integration: HERA supports seamless data import from standard formats (CSV, Excel), MATLAB tables, and NumPy arrays or Pandas DataFrames when using the python interface, facilitating integration into existing research pipelines. Example datasets and workflows demonstrating practical applications are included in the repository.
- Accessibility: HERA can be installed by cloning the
GitHub repository, via the
hera-matlabPython interface on PyPI, or deployed as a standalone application that requires no MATLAB license. The Python interface enables license-free integration into standard data science pipelines, requiring only a MATLAB Runtime. The MATLAB toolbox and standalone application feature an interactive CLI that guides users through the analysis without programming expertise, while an API and JSON Configuration allow for automated batch processing.
For detailed information on the algorithmic background, we refer to the Ranking Logic and Methodology, the Bootstrap Logic and Convergence, and the Methodological Guidelines and Limitations pages. An Example Analysis using HERA on synthetic data is also available.