Convergence Analysis for Robust Mode
This document provides an overview of the validation performed for the Robust Convergence Mode in HERA.
Overview
The purpose of this analysis was to ensure that the default parameters used in the robust convergence mode are effective across a variety of data scenarios. Rather than a formal theoretical study, this was a practical validation using Monte Carlo simulations to verify that convergence is reliably achieved within the default iteration limits across typical use cases.
Additionally, we evaluated the accuracy of the results by comparing them against reference values generated with a very high number of bootstrap iterations. This ensures that the convergence criteria not only stop at a reasonable time but also produce results with acceptable error relative to the reference values.
The results confirm that the default settings are appropriate for the vast majority of scenarios, yielding both stable and accurate outcomes.
To ensure reproducibility and fair comparability, we utilized a deterministic seeding scheme for all simulations. A fixed base seed controls the synthetic data generation, guaranteeing that both the convergence checks and the reference benchmarks operate on identical datasets. The bootstrap resampling seeds, however, are deliberately offset to ensure statistical independence between the convergence tests and the high-precision reference computations. The detailed results of this validation study can be viewed in the repository under tests.
Analysis Design & Constraints
To validate the robustness of the default parameters, we simulated a diverse set of conditions.
Fixed Parameters
It is important to note that the following parameters were treated as constants and thus their influence was not explicitly tested in this analysis:
- Step Size (\(B_{step}\))
- Tolerance (\(Tol\))
- Start Iterations (\(B_{start}\))
- End Iterations (\(B_{end}\))
These were held constant because the three parameters we did test (regarding data distribution and method variability) were considered the most critical factors influencing the stability of achieving a desired tolerance.
Evaluated Scenarios
We tested against multiple distribution types (Normal, Bimodal, Skewed, Likert) and sample sizes (\(n = 25 - 100\)), as well as varying method properties. To ensure robust findings, each of the eight scenarios was evaluated using \(N_{\text{sim}} = 50\) independent simulations, totaling 400 simulations across 2,400 distinct datasets and 3,600 benchmarked bootstrap settings. Typical Cliff's Delta effect magnitudes observed in the simulations ranged from 0.18 to 0.74.
Data Scenarios:
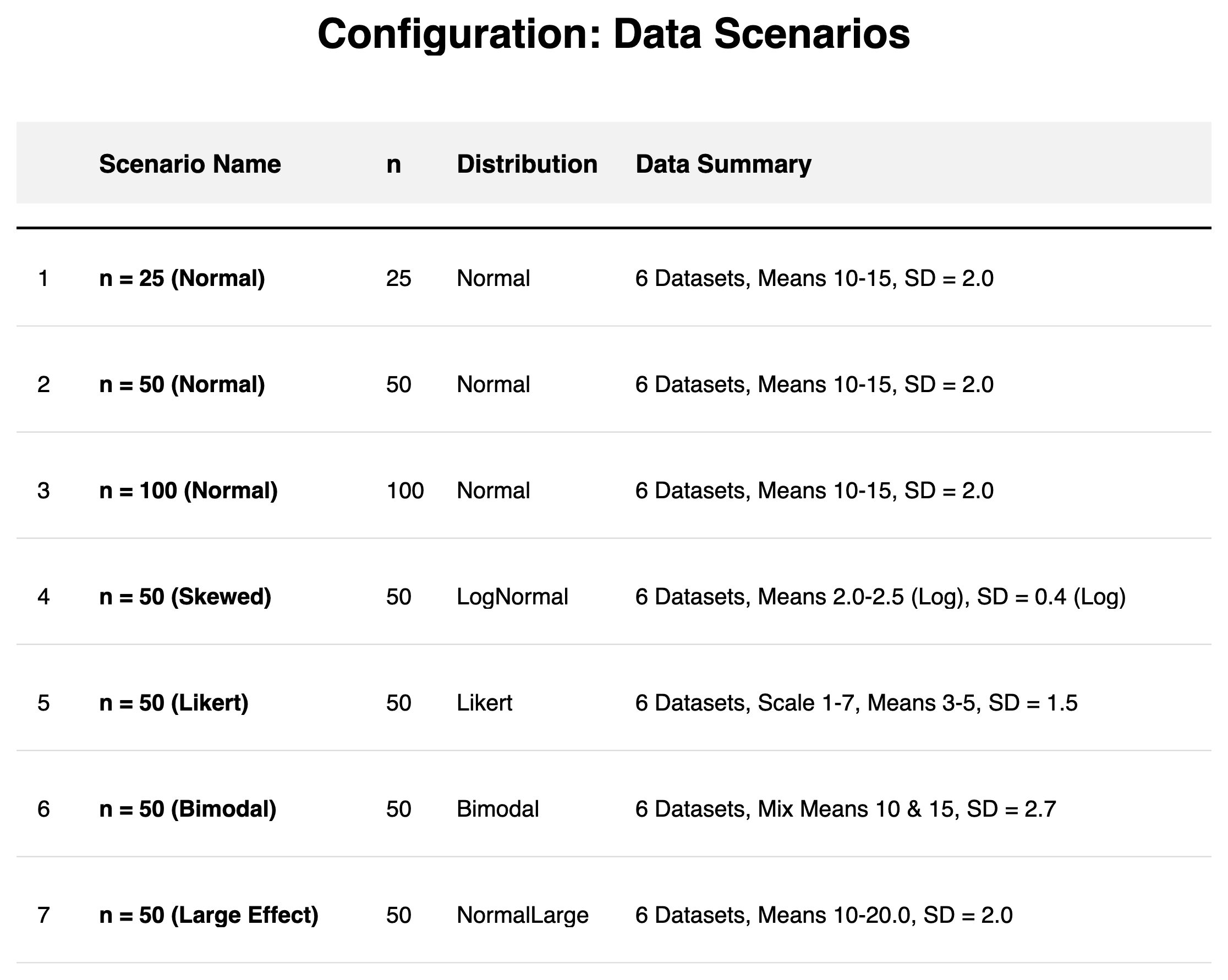
Method Configurations:
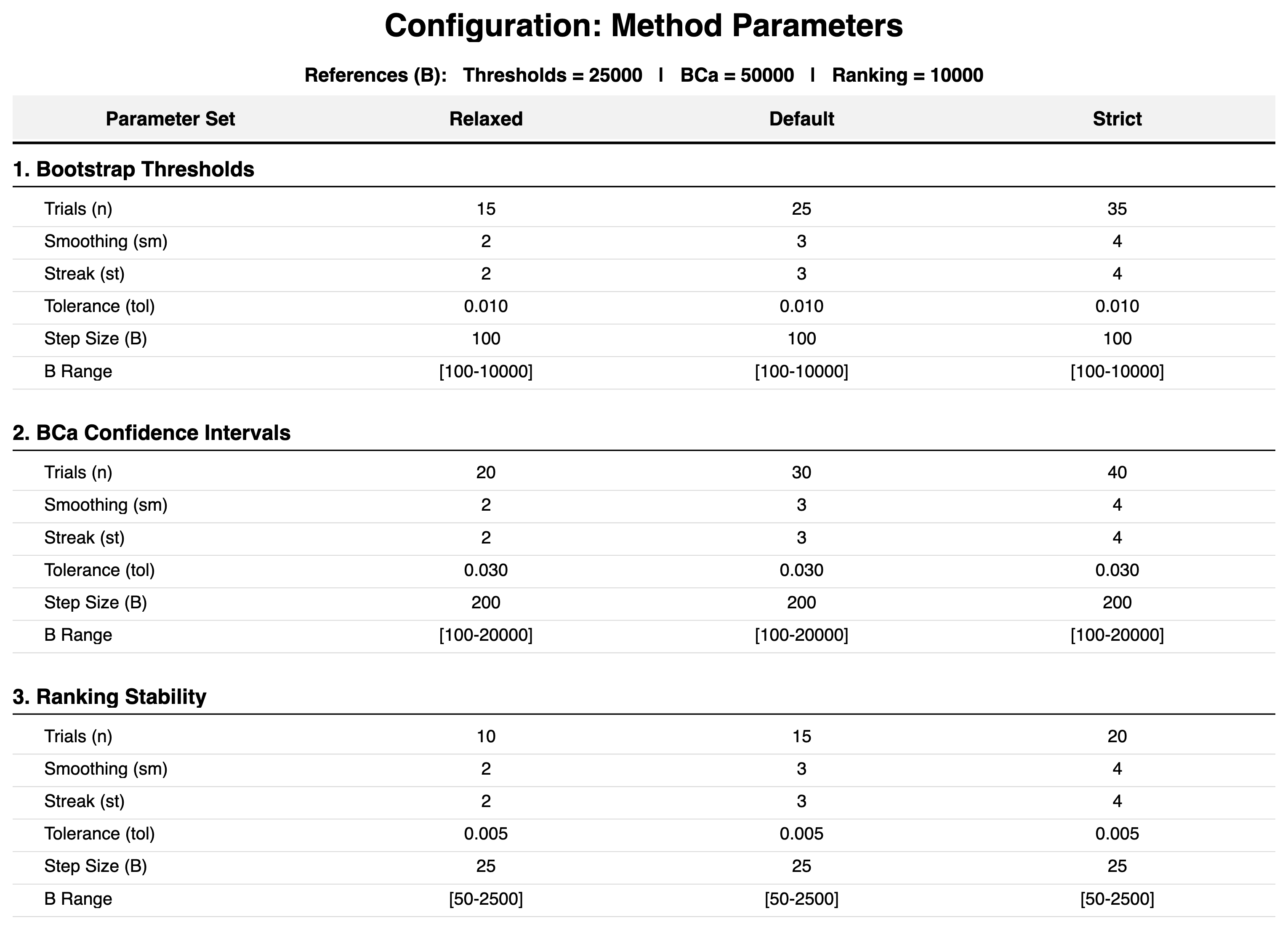
Analysis Scope
To isolate the behavior of individual convergence algorithms and ensure valid results across scenarios, the following principles and simplifications were applied:
Accuracy Metrics
To assess robustness, we quantify the estimation error against high-precision references.
- For BCa Confidence Intervals and Rankings, we use the relative percentage error to capture scaled deviations.
- For Cliff's Delta Thresholds (\(\theta_d\)), which operate on a fixed \([0, 1]\) interval, we use the absolute deviation. This hybrid approach ensures stable validation even when differences are near zero, preventing disproportionately high percentage errors.
Accuracy Focus
- Thresholds: The validation focuses primarily on the Cliff's Delta threshold (\(\theta_d\)). As a non-parametric effect size, Cliff's Delta is the main driver for determining the direction of superiority (dominance) in HERA's ranking system. The RelDiff threshold (\(\theta_{\text{RelDiff}}\)) was excluded from direct convergence validation because its final value can be capped by a SEM-based lower limit (see Ranking Logic), meaning the raw bootstrap estimate alone does not fully reflect the intended algorithmic output for that specific metric.
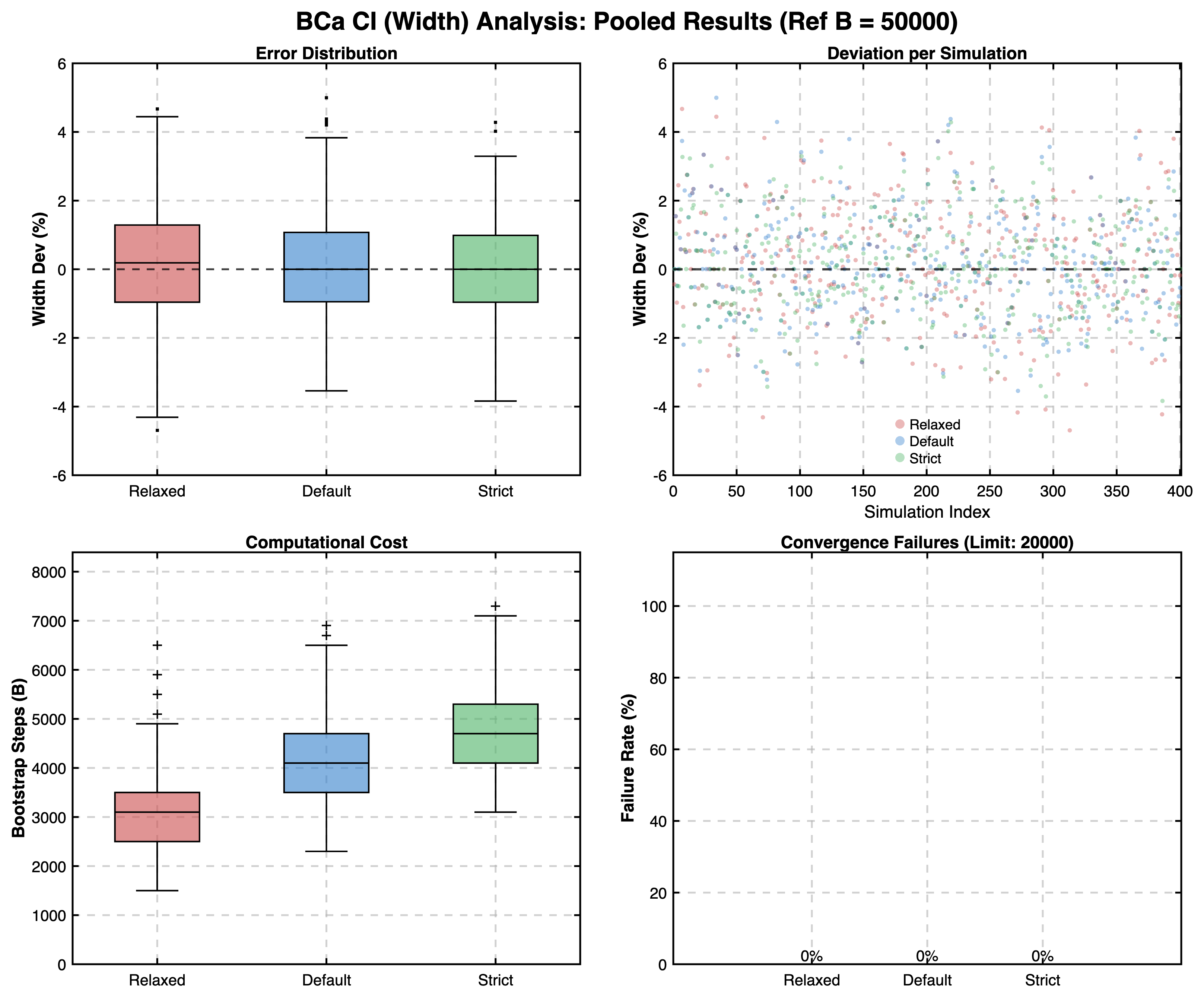
- BCa Intervals: We specifically evaluate the accuracy of the width of the Cliff's Delta confidence interval. Width is the primary determinant of statistical precision and uncertainty quantification in the BCa method. This assessment is performed on a single, representative pairwise comparison per dataset, which serves as a proxy for the stability of the entire resampling process across all pairs. Cliff's Delta was chosen as its precision is more important for the ranking logic.
- Ranking Stability: A single-metric ranking (Stage 1 only) using the Mean Rank was chosen as a robust proxy for the overall stability of the discrete order. Multi-metric rankings (e.g., Stage 1 & 2) involve more complex hierarchies that can mask fundamental convergence characteristics. Validating Stage 1 ensures better traceability of the bootstrap behavior.
- Isolation of Ranking Convergence: To focus purely on the ranking bootstrap's stability, the ranking phase was validated using fixed reference thresholds (\(\theta_d, \theta_{\text{RelDiff}}\)) derived from the separate high-precision run. This prevents variability in threshold estimation from confounding the results for ranking convergence. Therefore, we cannot assess the sensitivity of the ranking convergence to the variability of the thresholds.
Results
We evaluated the performance of the Robust Mode based on two key criteria: Convergence Success (did it finish?) and Accuracy (were the results correct?).
1. Convergence Frequency
In our analysis, we observed that:
- The Robust Mode achieved exceptionally high convergence rates.
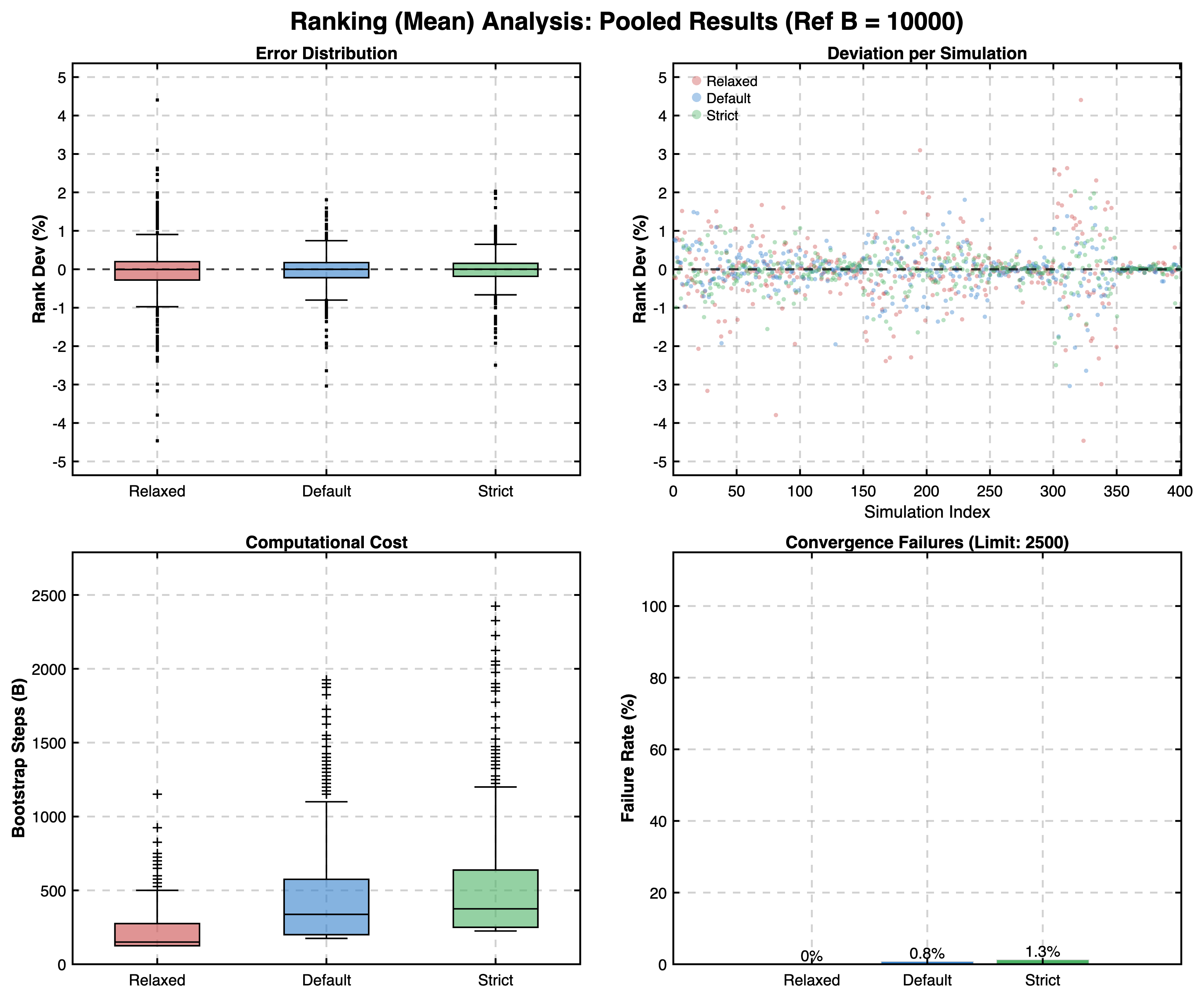
- The Ranking phase was the only area where non-convergence was observed, and even then, it occurred in 0.8% of ranking cases. In these instances, the Elbow Method fallback was engaged, and the inclusion of these fallback estimates did not negatively impact the aggregate error rates.
- For all other metrics (BCa Intervals, Thresholds), convergence rates were 100%.
2. Accuracy
Beyond simply checking for convergence, we also validated the accuracy of the results.
We compared the outcomes of the Robust Mode against "Gold Standard" reference values generated with very high bootstrap iteration counts independently for each simulation within the different scenarios:
- Thresholds: \(B_{ref} = 25{,}000\)
- BCa Confidence Intervals: \(B_{ref} = 50{,}000\)
- Ranking Stability: \(B_{ref} = 10{,}000\)
The goal was to analyze the pooled distribution of errors (deviation from reference) to ensure that the convergence method yields results that are not just stable, but also practically in line with high-precision reference benchmarks in a variety of data distributions and sample size scenarios.
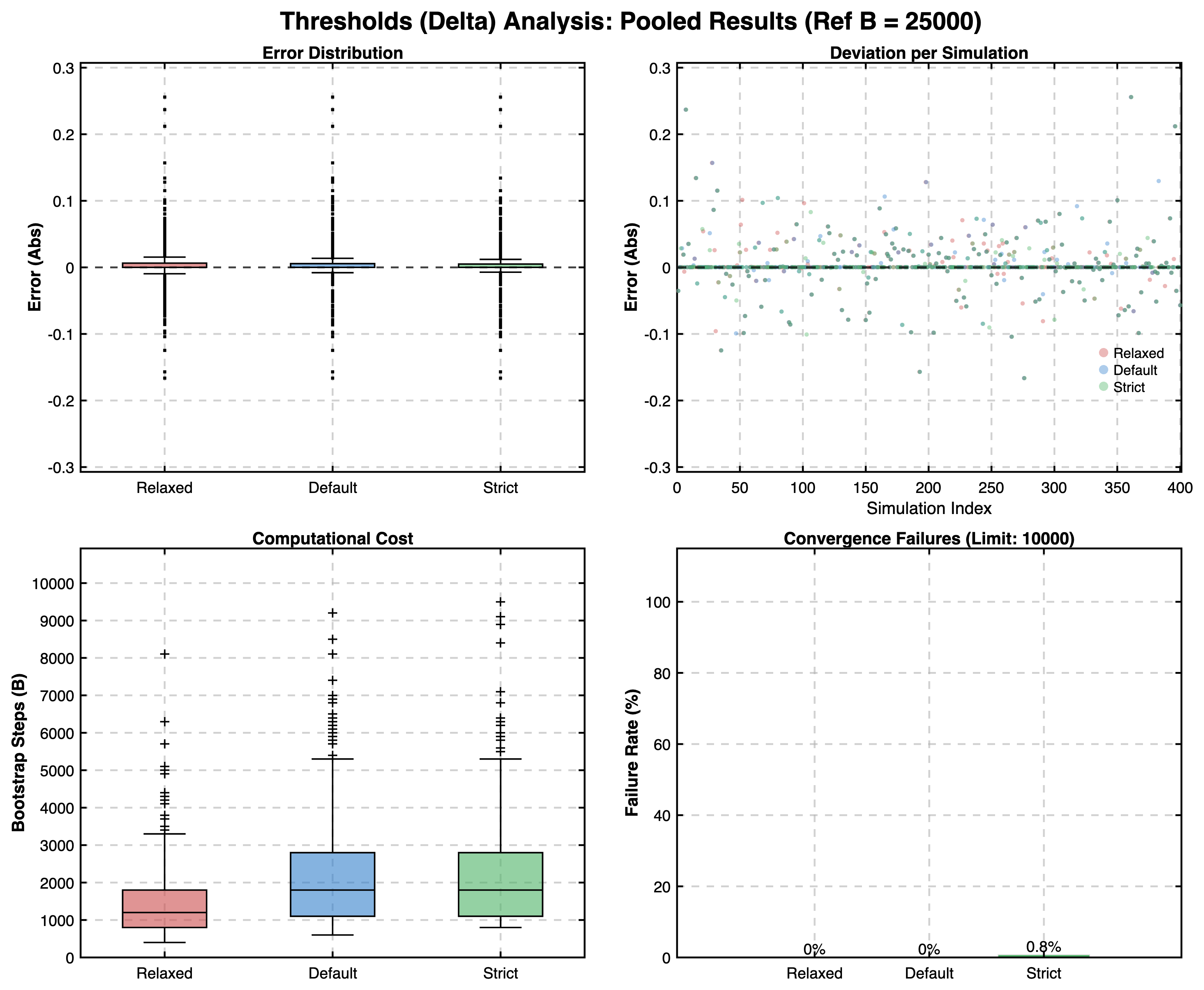
The results confirmed that the Robust Mode produces estimates with negligible deviation from reference values across all simulated scenarios. For BCa and Ranking, relative errors were typically well below 5%. For Cliff's Delta thresholds, the pooled median absolute deviation was 0, with the interquartile range (IQR) typically below \(0.02\), and 95% of the pooled estimates ranged within an absolute deviation of \(\pm 0.10\) from the reference.
This confirms that the averaged convergence criteria in HERA ensure high precision across all metrics.
Pooled Results
Ranking Convergence:
BCa Confidence Interval Convergence:
Threshold Convergence:
Discussion
The convergence analysis confirms that HERA's adaptive algorithm effectively determines stable estimates without a priori defined iteration counts. Pooled median errors remain near zero relative to high-precision reference values across all scenarios.
Stability Drivers
- Precision of Thresholds: Precision is exceptionally high because thresholds are derived from the distribution of medians, which naturally strongly resists resampling fluctuations (pooled median absolute error was 0.00).
- Resistance of Ranks: The minimal percentage error in Ranking results (pooled IQR of \([-0.2\%, +0.2\%]\)) is largely due to the discrete, ordinal nature of ranks. Unlike continuous metrics, ranks only shift when differences cross distinct, quantized intervals, making them inherently resistant to minor bootstrap fluctuations.
Parameter Sensitivity
The validation utilized three experimental parameter sets—Relaxed, Strict, and the standard Default—to benchmark the algorithm's susceptibility to changes in smoothing_window, n_trials, and convergence_streak_needed. These are not intended as user-facing "modes" but served as a sensitivity analysis.
- Relaxed (Benchmarking Speed): Prioritizes speed. While significantly faster, this configuration carries a higher risk of terminating before true stability is reached, especially for BCa intervals.
- Strict (Benchmarking Rigor): Prioritizes high stability. It enforces rigorous checks that may lead to very high iteration counts, which can be computationally expensive and potentially redundant, leading to non-convergence in more cases when the algorithm fails to confirm the satisfaction of the specified tolerance.
- Default (Practical Standard): Designed to balance efficiency and reliability. Interestingly, the Default mode occasionally yielded better BCa interval accuracy than the Strict setting. This suggests that excessively high iteration counts can capture rare extreme bootstrap samples that increase variance without improving the central estimate.
Overall, the results suggest that the algorithmic decisions are largely insensitive to variations in the tested parameters and confirm that the Default settings should provide a safe and effective balance for most general applications without requiring manual tuning.
Limitations
Despite the overall high precision, several methodological limitations should be considered.
- Global Stability vs. Individual Metrics: Algorithmic convergence is determined by a global stability indicator. While this averaged approach shows excellent accuracy, it is theoretically possible for the global curve to satisfy the stopping criteria before every individual metric or effect size has fully stabilized. Visual inspection of individual convergence trajectories remains recommended.
- Outliers & Boundary Sensitivity: While the median error is zero, absolute deviations of up to approximately 0.26 occurred as extreme outliers in scenarios with small sample sizes or large true effects. In cases where the true effect is near a threshold boundary, deviations of this magnitude could influence the final ranking outcome.
- Non-Convergence Risk: Rare cases (\(0.8\%\)) of non-convergence in the ranking phase demonstrate that automated checks are not an absolute guarantee. In these instances, the Elbow Method is utilized, which represents a pragmatic compromise to provide a heuristic fallback that should be critically evaluated by the user.
Warning
Users should always critically evaluate the automatically generated diagnostic convergence plots to verify stability in their specific application context. If plots indicate residual instability or premature termination, stability parameters should be adjusted. For practical advice, see Troubleshooting Convergence.
Conclusion
Our analysis confirms that the Default settings provided with HERA should be a safe choice for general usage, achieving convergence in 99.2% of tested Ranking cases and 100% of other cases, while maintaining high accuracy against reference standards.
Computational Note
The complete analysis (8 scenarios × 50 independent simulations × 6 different candidates ranked per scenario, comprising 2,400 distinct datasets) was performed on a standard consumer laptop (Base Model Apple 16" 2021 M1 MBP, 16 GB RAM) in approximately 11.5 hours. For each simulation, high-precision reference values were independently derived (up to B=50,000 for BCa), followed by convergence tests for all three modes (Relaxed, Default, Strict) utilizing 10–40 stability trials per B-step. This demonstrates the computational efficiency of the parallelized MATLAB implementation.
Full Report
For a comprehensive look at the data, including specific breakdowns for each distribution type, please refer to the generated PDF report:
Download Full Report of all Results (PDF)
Running Your Own Analysis
You can perform this analysis yourself to verify the robustness of your own changes or to test different parameter configurations. The analysis is integrated directly into the start_ranking command.
Syntax
% Standard executions (Interactive CLI)
HERA.start_ranking('convergence', 'true', [options])
% Advanced executions (JSON Configurations)
HERA.start_ranking('convergence', 'path/to/my_config.json')
Options
'logPath': (Optional) Specifies where the results and reports should be saved.'interactive': Opens a folder selection dialog.'path/to/folder': Uses the specified path.''(default): Automatically saves toDocuments/HERA_convergence_Log.'sims': (Optional) Number of simulations per scenario (Default: 15). Higher values (e.g., 50-100) provide more robust statistics but take longer to run.
Examples
1. Run with Default Settings: This runs the standard analysis (15 sims/scenario) and saves to the default Documents folder.
HERA.start_ranking('convergence', 'true')
2. Select Output Folder Interactively: This prompts you to choose where to save the reports.
HERA.start_ranking('convergence', 'true', 'logPath', 'interactive')
3. Run a High-Precision Study: Run 50 simulations per scenario for higher statistical power.
HERA.start_ranking('convergence', 'true', 'sims', 50)
4. Run with a Custom JSON Configuration:
For full control over the analysis parameters like RAM target, random seed offsets or simulation quantities, you can build a .json configuration file. This skips the standard start_ranking options entirely.
HERA.start_ranking('convergence', 'path/to/convergence_config.json')
JSON Configuration
You can structure your configuration file with a minimal setup, or specify all available parameters for full control.
Note
All parameters in the JSON configuration are entirely optional. The minimal required JSON file is just an empty
userInputobject ({ "userInput": {} }), from which standard defaults will fill all missing values.
Minimal Example Configuration
{
"userInput": {
"n_sims_per_cond": 10,
"output_dir": "/Users/Name/Results"
}
}
Full Example Configuration
This example shows all possible parameters with their default values for a convergence analysis.
Parameters (e.g., inside system, modes, scenarios, or refs) must be nested correctly as shown.
{
"userInput": {
"n_sims_per_cond": 15,
"output_dir": " ",
"system": {
"num_workers": "auto",
"target_memory": "auto"
},
"N": 6,
"selected_methods": ["thr", "bca", "rnk"],
"selected_modes": ["Relaxed", "Default", "Strict"],
"num_scenarios": 8, // Shortcut (Used only if selected_scenarios is missing)
"selected_scenarios": [1, 2, 3, 4, 5, 6, 7, 8],
"scenarios": [
{ "name": "Baseline-S", "n": 25, "Dist": "Normal", "Base": 10.0, "Step": 0.75, "End": null, "Base2": null, "SD": 2.0 },
{ "name": "Baseline-M", "n": 50, "Dist": "Normal", "Base": 10.0, "Step": 0.75, "End": null, "Base2": null, "SD": 2.0 },
{ "name": "Baseline-L", "n": 100, "Dist": "Normal", "Base": 10.0, "Step": 0.75, "End": null, "Base2": null, "SD": 2.0 },
{ "name": "Skewness", "n": 50, "Dist": "Skewed", "Base": 2.0, "Step": 0.10, "End": null, "Base2": null, "SD": 0.4 },
{ "name": "Quantization", "n": 50, "Dist": "Likert", "Base": 3.0, "Step": null, "End": 5.0, "Base2": null, "SD": 1.5 },
{ "name": "Bimodality", "n": 50, "Dist": "Bimodal", "Base": 10.0, "Step": 1.50, "End": null, "Base2": 15.0, "SD": 1.0 },
{ "name": "Sensitivity", "n": 50, "Dist": "Small Effect", "Base": 10.0, "Step": 0.27, "End": null, "Base2": null, "SD": 2.0 },
{ "name": "Discrimination", "n": 50, "Dist": "Large Effect", "Base": 10.0, "Step": 1.50, "End": null, "Base2": null, "SD": 2.0 }
],
"simulation_seed": 123,
"bootstrap_seed_offset": 1000,
"scenario_seed_offset": 10000,
"reference_seed_offset": 5000,
"reference_step_offset": 1000,
"modes": {
"Relaxed": {
"thr": { "n": 15, "sm": 2, "st": 2, "tol": 0.01, "start": 100, "step": 100, "end": 10000 },
"bca": { "n": 20, "sm": 2, "st": 2, "tol": 0.03, "start": 100, "step": 200, "end": 20000 },
"rnk": { "n": 10, "sm": 2, "st": 2, "tol": 0.005, "start": 50, "step": 25, "end": 2500 }
},
"Default": {
"thr": { "n": 25, "sm": 3, "st": 3, "tol": 0.01, "start": 100, "step": 100, "end": 10000 },
"bca": { "n": 30, "sm": 3, "st": 3, "tol": 0.03, "start": 100, "step": 200, "end": 20000 },
"rnk": { "n": 15, "sm": 3, "st": 3, "tol": 0.005, "start": 50, "step": 25, "end": 2500 }
},
"Strict": {
"thr": { "n": 35, "sm": 4, "st": 4, "tol": 0.01, "start": 100, "step": 100, "end": 10000 },
"bca": { "n": 40, "sm": 4, "st": 4, "tol": 0.03, "start": 100, "step": 200, "end": 20000 },
"rnk": { "n": 20, "sm": 4, "st": 4, "tol": 0.005, "start": 50, "step": 25, "end": 2500 }
}
},
"refs": {
"thr": 25000,
"bca": 50000,
"rnk": 10000
}
}
}
Parameter Dictionary
| Category | Parameter | Type | Default | Description |
|---|---|---|---|---|
| Input/Output | output_dir |
string | - |
Path to save results and reports. Empty defaults to Documents/HERA_convergence_Log. |
| Logic | n_sims_per_cond |
int | 15 |
Number of simulations per scenario. Higher values (e.g. 50-100) provide more robust statistics but take longer to run. |
selected_methods |
array | ["thr", "bca", "rnk"] |
Array of strings specifying which components to validate. Any combination of "thr", "bca", "rnk". (Note: Thresholds are always calculated internally to provide underlying baseline references for BCa and Ranking). |
|
selected_modes |
array | ["Relaxed", "Default", "Strict"] |
Array of strings specifying which bootstrap convergence parameter profiles to evaluate. Any combination of "Relaxed", "Default", "Strict". |
|
| Data Scenarios | N |
int | 6 |
Number of candidates in the scenarios (recommended 3-15, min 2). |
num_scenarios |
int | 8 |
Shortcut to run only the first X scenarios. Only used if selected_scenarios is omitted. |
|
selected_scenarios |
array | [1..8] |
Array of specific scenario indices to execute (e.g., [1, 3, 5]). Takes priority over num_scenarios. |
|
scenarios |
array | [...] |
Array of objects to customize core data scenarios. You can fully customize defaults or only overwrite specific fields. | |
scenarios.name |
string | - |
Name of the specific scenario. | |
scenarios.n |
int | - |
True sample size \(n\) drawn per dataset (minimum 5). | |
scenarios.Dist |
string | - |
Probability Distribution (Normal, Skewed, Likert, Bimodal, Small Effect, Large Effect). |
|
scenarios.Base |
double | - |
The starting mean (\(\mu_0\)) for the first candidate. | |
scenarios.Step |
double | - |
The mean gap increment (\(\mu_{i+1} = \mu_i + \text{Step}\)) for scaling datasets dynamically via \(N\). Can be null if the distribution uses fixed boundaries (e.g., Likert). |
|
scenarios.End |
double | null |
Max value boundary. Usually null, except when required by bounded distributions like Likert. |
|
scenarios.Base2 |
double | null |
Secondary Mean \(\mu_2\). Usually null, except when rendering a mixed Bimodal distribution layout. |
|
scenarios.SD |
double | - |
Standard Deviation / underlying noise (\(\sigma\)). | |
| System | num_workers |
int/str | "auto" |
Number of parallel workers. "auto" uses parcluster('local').NumWorkers to utilize all local available cores. |
system.target_memory |
int/str | "auto" |
Target memory per chunk (MB). Overrides dynamic RAM detection with fixed limit. Capping the memory footprint per parallel worker prevents out-of-memory errors during batch processing. If "auto", HERA detects available RAM (reserves 25 MB per 1 GB) and automatically balances simultaneous simulations. |
|
| Seeds & RNG | simulation_seed |
int | 123 |
Seeds the main study. Can be locked for strict reproduction. |
bootstrap_seed_offset |
int | 1000 |
Keeps the internal evaluations structurally independent of the outer iterations. | |
scenario_seed_offset |
int | 10000 |
Ensures different tested scenarios don't overlap in their RNG seeds. HERA automatically scales this offset based on the number of simulations. | |
reference_seed_offset |
int | 5000 |
Establishes the gap between simulated data generated and reference calculations executed. | |
reference_step_offset |
int | 1000 |
Ensures that high-precision references for Thresholds, BCa, and Ranking are statistically independent by applying multipliers (\(1 \cdot \text{offset}\), \(2 \cdot \text{offset}\), \(3 \cdot \text{offset}\)) to the reference base seed. | |
| Convergence Modes | modes |
struct | - |
Specify profiles (Relaxed, Default, Strict). Missing properties fall back to package defaults. Each profile contains sub-objects for algorithms (thr, bca, rnk). |
modes.[Profile].[Algo].n |
int | - |
Number of Bootstrap checks per evaluation batch. Default: 15, 25, 35 (Thr); 20, 30, 40 (BCa); 10, 15, 20 (Rnk). |
|
modes.[Profile].[Algo].sm |
int | - |
Smoothing Window: A rolling average to mitigate local bootstrap noise. Defaults match st. |
|
modes.[Profile].[Algo].st |
int | - |
Streak parameter: Required consecutive successes within tolerance to achieve convergence. Default: 2, 3, 4. |
|
modes.[Profile].[Algo].tol |
double | - |
Precision Tolerance: Allowed deviation for stability. Default: 0.01 (Thr), 0.03 (BCa), 0.005 (Rnk). |
|
modes.[Profile].[Algo].start |
int | - |
Starting Iterator threshold (Min B). Default: 100 (Thr, BCa), 50 (Rnk). |
|
modes.[Profile].[Algo].step |
int | - |
Step size: Amount of iterations executed between evaluations. Default: 100 (Thr), 200 (BCa), 25 (Rnk). |
|
modes.[Profile].[Algo].end |
int | - |
End limit (Max B): Fallback point if convergence is not reached. Default: 10000 (Thr), 20000 (BCa), 2500 (Rnk). |
|
| References | refs.thr |
int | 25000 |
Iterations for the high-precision reference values ("The Truth") for Thresholds. |
refs.bca |
int | 50000 |
Iterations for the high-precision reference values for BCa Confidence Intervals. | |
refs.rnk |
int | 10000 |
Iterations for the high-precision reference values for Ranking Stability. |
👉 For an in-depth explanation on how exactly sm, st, tol and the iteration limits operate during runtime, see: Convergence Modes & Bootstrap Configuration (Auto-Convergence)