Convergence Analysis for Robust Mode
This document provides an overview of the validation performed for the Robust Convergence Mode in HERA.
Overview
The purpose of this analysis was to ensure that the default parameters used in the robust convergence mode are effective across a variety of data scenarios. Rather than a formal theoretical study, this was a practical validation using Monte Carlo simulations to verify that convergence is reliably achieved within the default iteration limits across typical use cases.
Additionally, we evaluated the accuracy of the results by comparing them against reference values generated with a very high number of bootstrap iterations. This ensures that the convergence criteria not only stop at a reasonable time but also produce results with acceptable error relative to the reference values.
The results confirm that the default settings are appropriate for the vast majority of scenarios, yielding both stable and accurate outcomes.
To ensure reproducibility and fair comparability, we utilized a deterministic seeding scheme for all simulations. A fixed base seed controls the synthetic data generation, guaranteeing that both the convergence checks and the reference benchmarks operate on identical datasets. The bootstrap resampling seeds, however, are deliberately offset to ensure statistical independence between the convergence tests and the high-precision reference computations.
Analysis Design & Constraints
To validate the robustness of the default parameters, we simulated a diverse set of conditions.
Fixed Parameters
It is important to note that the following parameters were treated as constants and thus their influence was not explicitly tested in this analysis:
- Step Size (\(B_{step}\))
- Tolerance (\(Tol\))
- Start Iterations (\(B_{start}\))
- End Iterations (\(B_{end}\))
These were held constant because the three parameters we did test (regarding data distribution and method variability) were considered the most critical factors influencing the stability of achieving a desired tolerance.
Evaluated Scenarios
We tested against multiple distribution types (Normal, Bimodal, Skewed, Likert) and sample sizes, as well as varying method properties. Typical Cliff's Delta effect magnitudes observed in the simulations ranged from 0.29 to 0.86.
Data Scenarios:
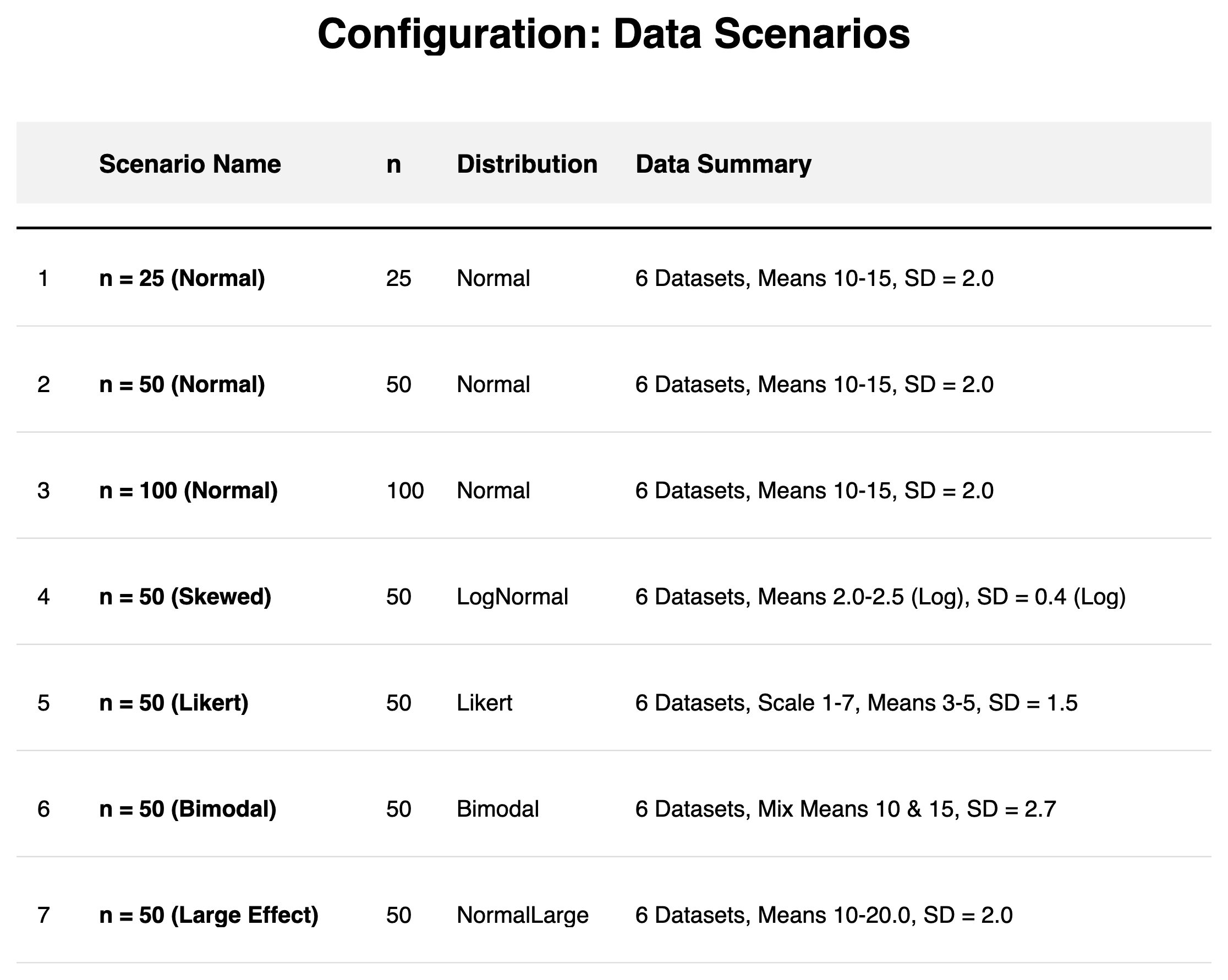
Method Configurations:
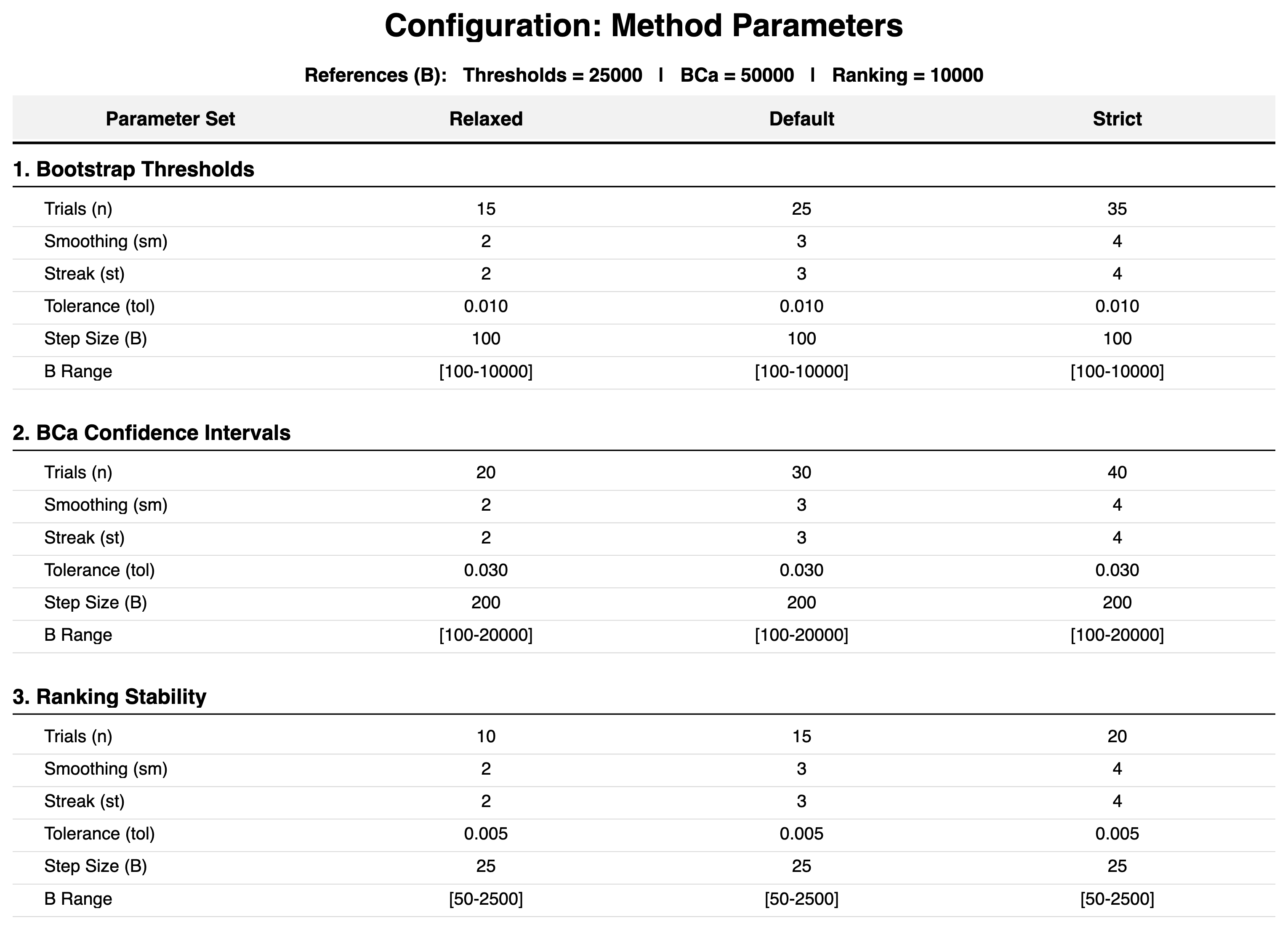
Analysis Scope
To isolate the behavior of individual convergence algorithms, the following principles and simplifications were applied:
- Accuracy Metrics: To assess the overarching robustness, we quantify the estimation error against the high-precision references. For BCa Confidence Intervals and Rankings, we calculate the relative percentage error. For Cliff's Delta Thresholds (\(\theta_d\)), which operate on a fixed \([0, 1]\) interval, we use the absolute deviation to ensure stable validation even for very small reference values.
- Effect Size Calculation: Both Cliff's Delta and Relative Difference are always calculated, and the convergence criterion is based on the averaged stability of both. This design choice allows us to test whether the averaged convergence approach produces accurate individual estimates despite relying on a combined stability indicator.
- Ranking Stability: A single-metric ranking (M1 only) was used to provide a stable reference point. Multi-metric rankings (M1_M2, M1_M2_M3) may exhibit different convergence characteristics due to increased complexity.
- Thresholds for Ranking: Pre-calculated reference thresholds were used to isolate the ranking convergence behavior from threshold estimation variability.
Validation Results
We evaluated the performance of the Robust Mode based on two key criteria: Convergence Success (did it finish?) and Accuracy (were the results correct?).
1. Convergence Frequency
In our analysis, we observed that:
- The Robust Mode achieved exceptionally high convergence rates.
- The Ranking phase was the only area where non-convergence was observed, and even then, it occurred in 0.3% of ranking cases. In these instances, the Elbow Method fallback was engaged, and the inclusion of these fallback estimates did not negatively impact the aggregate error rates.
- For all other metrics (BCa Intervals, Thresholds), convergence rates were 100%.
2. Accuracy Validation
Beyond simply checking for convergence, we also validated the accuracy of the results.
- We compared the outcomes of the Robust Mode against "Gold Standard" reference values generated with very high bootstrap iteration counts:
- Thresholds: \(B_{ref} = 25{,}000\)
- BCa Confidence Intervals: \(B_{ref} = 50{,}000\)
- Ranking Stability: \(B_{ref} = 10{,}000\)
- The goal was to analyze the distribution of errors (deviation from reference) to ensure that the convergence method yields results that are not just stable, but also practically in line with the theoretical limits.
- The results confirmed that the Robust Mode produces estimates with acceptably small deviation from reference values across all simulated scenarios. For BCa and Ranking, relative errors were typically well below 5%, while for Cliff's Delta thresholds, the absolute deviation remained consistently minimal (typically < 0.05).
- This confirms that the averaged convergence criteria in HERA ensure high precision across all metrics.
Global Results Summary
Ranking Convergence:
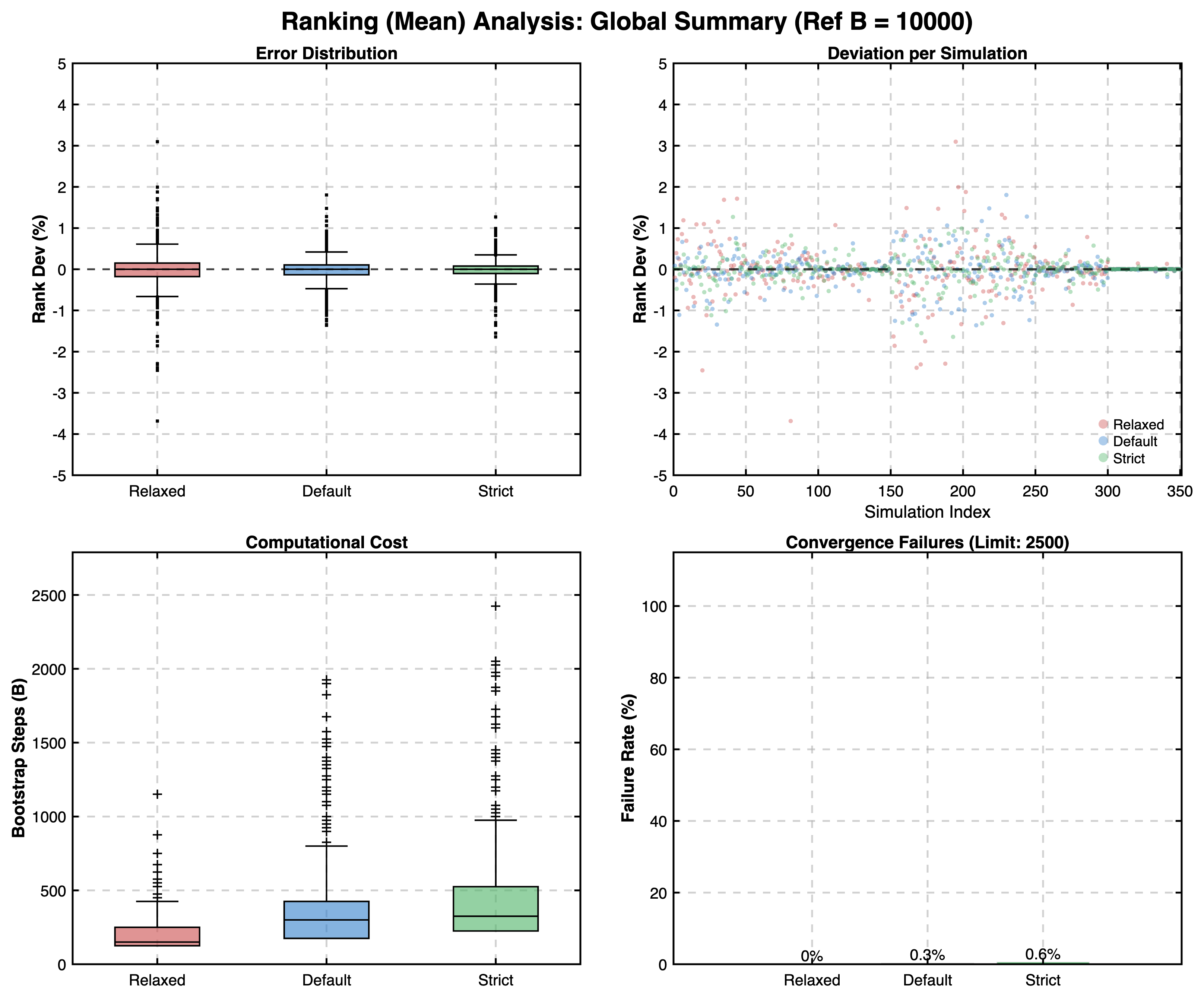
BCa Confidence Interval Convergence:
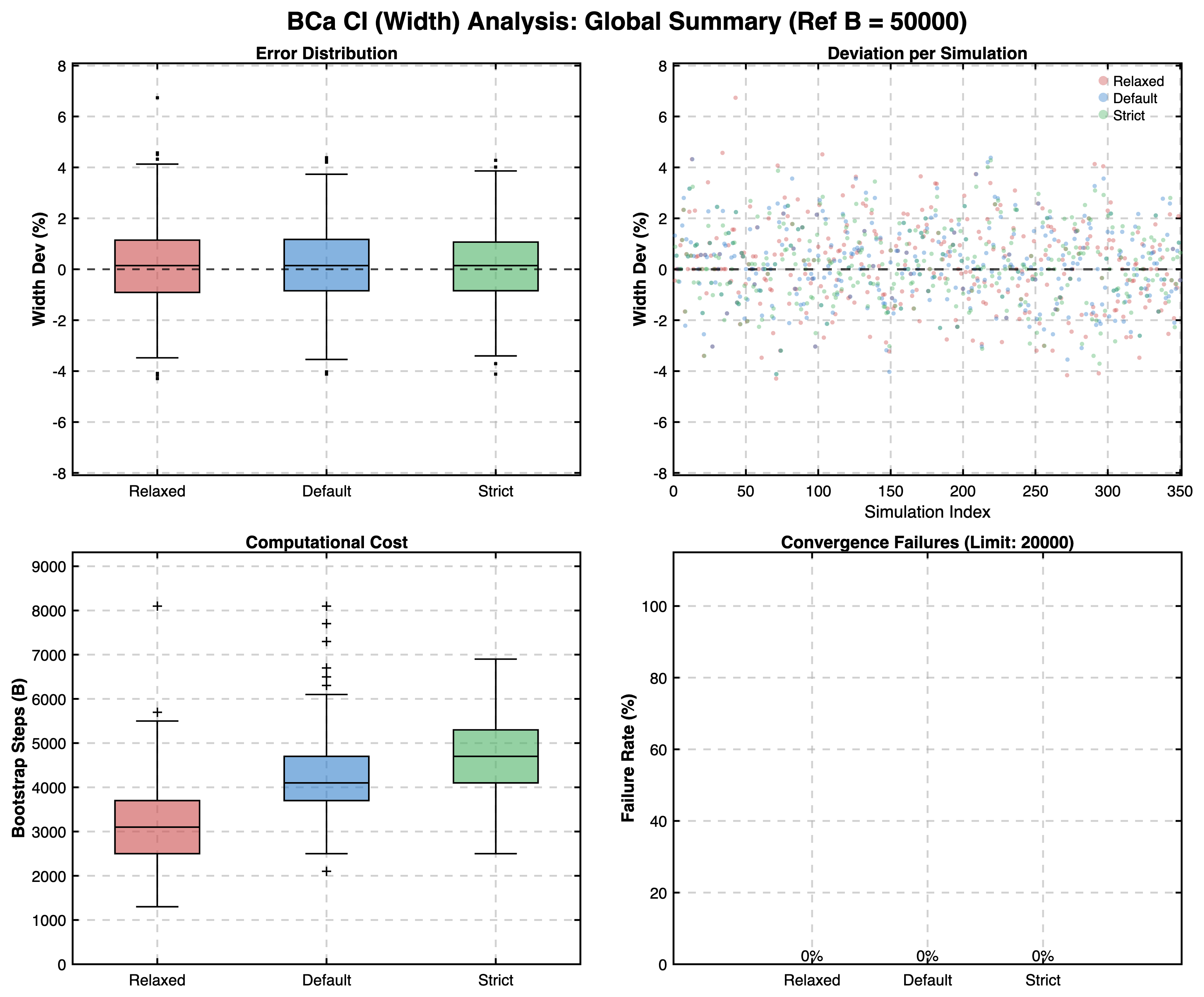
Threshold Calculations:
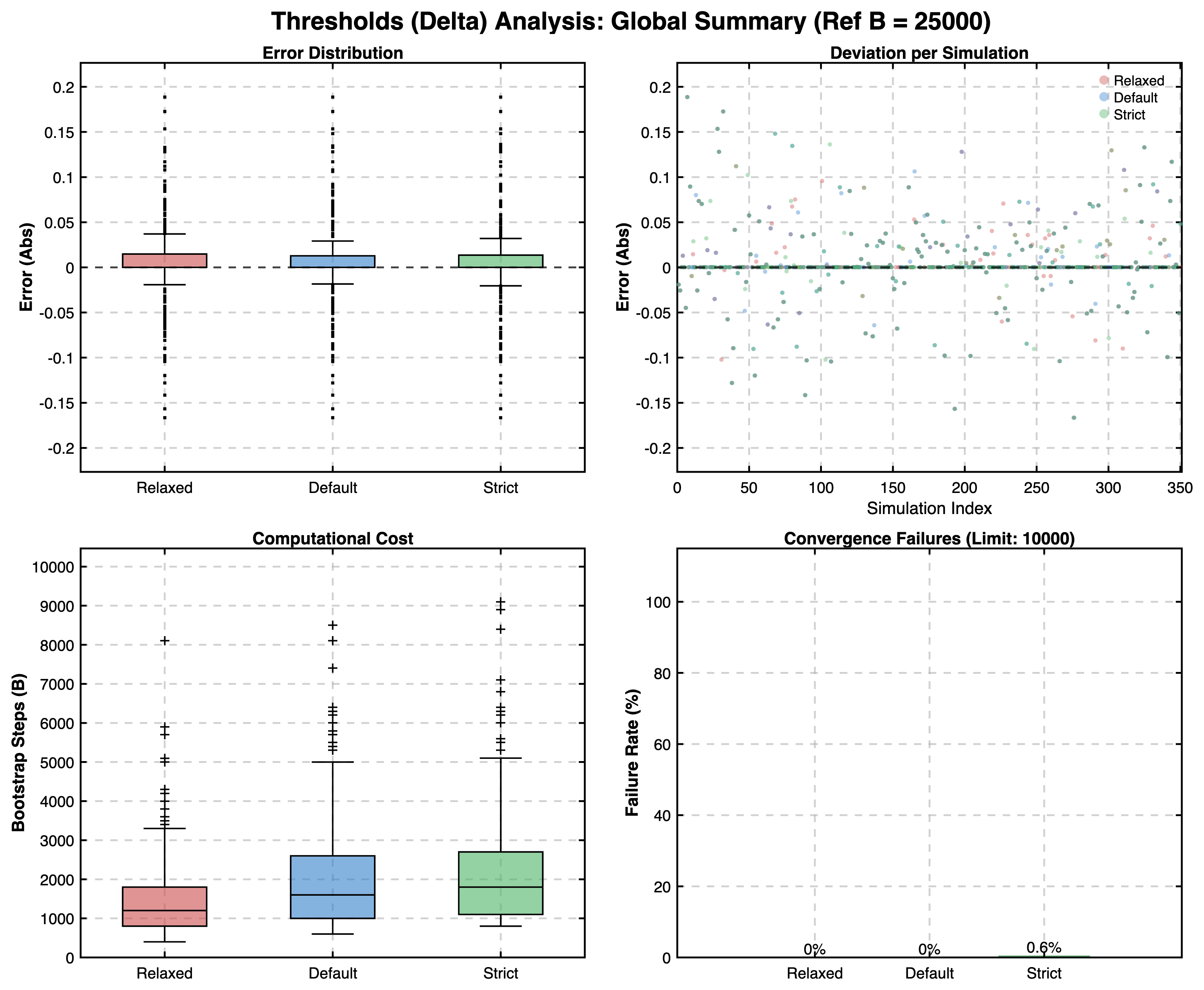
Discussion: Convergence Modes
Based on these results, we can discuss the theoretical implications of the different convergence parameters one could set in HERA compared to the default settings:
- Relaxed: Prioritizes speed. While significantly faster, it carries a higher risk of terminating before true stability is reached, especially in complex scenarios and BCa confidence intervals.
- Strict: Prioritizes guaranteed stability. It enforces rigorous checks that may lead to very high iteration counts. While safer, this can be computationally expensive and potentially overkill for well-behaved datasets where the Default mode would suffice. Also it could lead to non-convergence in some cases for the desired tolerance.
- Default: Designed to balance efficiency and reliability, it seems to be the best option for general usage. Interestingly, in some tested scenarios it provides higher accuracy for the BCa confidence intervals compared to stricter settings when comparing to the reference values. This is likely because stricter settings with more iterations can occasionally include rare extreme bootstrap samples that increase variance without improving the central estimate.
Conclusion
Our analysis confirms that the Default settings provided with HERA should be a safe choice for general usage, achieving convergence in 99.7% of tested Ranking cases and 100% of other cases, while maintaining high accuracy against reference standards.
Computational Note
The complete analysis (7 scenarios × 50 independent simulations × 6 different candidates ranked per scenario, comprising 2,100 distinct datasets) was performed on a standard consumer laptop (Base Model Apple 16" 2021 M1 MBP, 16 GB RAM) in approximately 9 hours. For each simulation, high-precision reference values were independently derived (up to B=50,000 for BCa), followed by convergence tests for all three modes (Relaxed, Default, Strict) utilizing 10–40 stability trials per B-step. This demonstrates the computational efficiency of the parallelized MATLAB implementation.
Full Report
For a comprehensive look at the data, including specific breakdowns for each distribution type, please refer to the generated PDF report:
Download Full Combined Report (PDF)
Running Your Own Analysis
You can perform this analysis yourself to verify the robustness of your own changes or to test different parameter configurations. The analysis is integrated directly into the start_ranking command.
Syntax
% Standard executions (Interactive CLI)
HERA.start_ranking('convergence', 'true', [options])
% Advanced executions (JSON Configurations)
HERA.start_ranking('convergence', 'path/to/my_config.json')
Options
'logPath': (Optional) Specifies where the results and reports should be saved.'interactive': Opens a folder selection dialog.'path/to/folder': Uses the specified path.''(default): Automatically saves toDocuments/HERA_convergence_Log.'sims': (Optional) Number of simulations per scenario (Default: 15). Higher values (e.g., 50-100) provide more robust statistics but take longer to run.
Examples
1. Run with Default Settings: This runs the standard analysis (15 sims/scenario) and saves to the default Documents folder.
HERA.start_ranking('convergence', 'true')
2. Select Output Folder Interactively: This prompts you to choose where to save the reports.
HERA.start_ranking('convergence', 'true', 'logPath', 'interactive')
3. Run a High-Precision Study: Run 50 simulations per scenario for higher statistical power.
HERA.start_ranking('convergence', 'true', 'sims', 50)
4. Run with a Custom JSON Configuration:
For full control over the analysis parameters like RAM target, random seed offsets or simulation quantities, you can build a .json configuration file. This skips the standard start_ranking options entirely.
Note: All parameters in the JSON configuration are entirely optional. The minimal required JSON file is just an empty userInput object ({ "userInput": {} }), from which standard defaults will fill all missing values.
HERA.start_ranking('convergence', 'path/to/convergence_config.json')
Example JSON Configuration file:
{
"userInput": {
"n_sims_per_cond": 50,
"output_dir": "/Users/Name/Results",
"target_memory": 400,
"simulation_seed": 123,
"bootstrap_seed_offset": 1000,
"scenario_seed_offset": 10000,
"reference_seed_offset": 5000,
"reference_step_offset": 1000,
"modes": {
"Default": {
"thr": { "n": 25, "sm": 3, "st": 3, "tol": 0.01, "start": 100, "step": 100, "end": 10000 },
"bca": { "n": 30, "sm": 3, "st": 3, "tol": 0.03, "start": 100, "step": 200, "end": 20000 },
"rnk": { "n": 15, "sm": 3, "st": 3, "tol": 0.005, "start": 50, "step": 25, "end": 2500 }
},
"Relaxed": {
"bca": { "tol": 0.05 }
}
},
"refs": {
"thr": 25000,
"bca": 50000,
"rnk": 10000
}
}
}
target_memory: Overrides the dynamic RAM detection algorithm with a fixed limit (in MB).- What it means: It caps the memory footprint allowed per parallel worker during bootstrap batch processing. If the estimated memory for all iterations exceeds this limit, they are automatically split into smaller chunks to prevent out-of-memory errors.
- Default Calculation: If omitted, HERA automatically detects your system's available RAM to optimize performance. It reserves a safe memory buffer (25 MB per 1 GB of RAM, e.g., 400 MB for a 16 GB system) to prevent system overloads and automatically balances the number of simultaneous simulations based on your CPU cores and this memory limit to ensure the analysis runs as fast as possible without crashing.
simulation_seed: Seeds the main study. Can be locked for strict reproduction (fallback: 123).bootstrap_seed_offset: Keeps the internal evaluations structurally independent of the outer iterations (fallback: 1000).scenario_seed_offset: Ensures different tested scenarios don't overlap in their RNG seeds. HERA automatically scales this offset based on the number of simulations to ensure each scenario stays in its own unique random sequence.reference_seed_offset: Establishes the gap between simulated data generated and reference calculations executed (fallback: 5000).reference_step_offset: Ensures that the high-precision reference values for Thresholds, BCa, and Ranking are statistically independent of each other by applying multipliers (\(1 \cdot \text{offset}\), \(2 \cdot \text{offset}\), \(3 \cdot \text{offset}\)) to the reference base seed (fallback: 1000).modes: You can specify missing details (Relaxed,Default,Strict) specifically for each of the three algorithms (thrfor Thresholds,bcafor BCa CI,rnkfor Ranking), down to single parameters (start,step,end,sm,st,tol). Missing properties will automatically fall back to the package defaults. 👉 Bootstrap Configurationrefs: Defines the number of bootstrap iterations for the high-precision reference values ("The Truth").- Default: Thresholds \(25{,}000\), BCa Confidence Intervals \(50{,}000\), Ranking Stability \(10{,}000\).